2024年是人工智能爆发的一年,一系列大型语言模型(LLM)不断推出,并逐渐成为许多人科技生活的重要组成部分。
2024年是人工智能爆发的一年,一系列大型语言模型(LLM)不断推出,并逐渐成为许多人科技生活的重要组成部分。
然而,人工智能(AI)公司正在努力收集高质量的训练数据。换句话说,许多公司都“渴望”为其大规模人工智能模型提供训练数据。事实上,包括苹果、英伟达、Salesforce和Anthrophic在内的许多大型科技公司都卷入了一场关于人工智能训练数据的新争议,其中最引人注目的是指控利用YouTube海量丰富的视频内容来训练人工智能,这严重影响了数字内容版权问题。
为了解决这些问题,YouTube 将让创作者更好地控制第三方公司如何使用其内容来训练人工智能。 YouTube 团队的官方声明如下:
在接下来的几天里,我们将推出一项更新,允许创作者和视频版权所有者选择让第三方公司使用他们的内容来训练人工智能模型。此选项将直接显示在“第三方培训”下的 Studio 设置中。
通过启用此功能,创作者允许 xAI、Apple、Amazon、Anthropic、Meta、Microsoft、Nvidia、OpenAI 等公司使用他们的视频来训练各自的 AI 模型。但是,并非所有视频都符合条件。要被“选择”作为 AI 训练数据,视频必须满足以下条件:
- 该视频的版权所有者允许第三方使用该视频来训练人工智能。
- 视频隐私设置是公开的。
- 视频符合 YouTube 服务条款和社区准则。
但似乎许多人对大型科技公司利用其内容来训练人工智能模型并不满意。以 Bluesky 用户为例。在一位机器学习专家在 Bluesky 上发布了包含一百万条帖子的数据集后,该社交媒体平台的用户社区表达了愤怒。
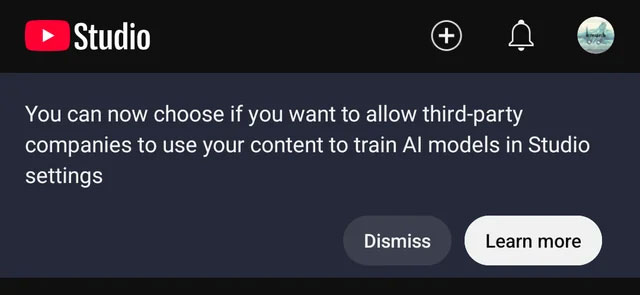 YouTube 将让第三方根据用户内容训练 AI 模型图 1
YouTube 将让第三方根据用户内容训练 AI 模型图 1
许多用户加入 Bluesky 是为了逃离 X(以前称为 Twitter)等平台,埃隆·马斯克的 xAI 在其中使用用户帖子来训练其人工智能 Grok。他们以为自己找到了一个更安全的空间,但这一事件让许多人意识到,即使在 Bluesky 上,他们的内容也可能在未经他们同意的情况下被使用。
在英国,包括出版商、作家和摄影师在内的近 40 个创意团体在参加有关人工智能和创意产业的咨询时,敦促政府加强版权保护。人工智能创意权联盟主张建立许可市场,以实现生成人工智能中创意内容的公平使用,确保内容创作者保留对其工作和报酬的控制权。
2024 年 8 月,美国艺术家赢得了具有里程碑意义的人工智能版权诉讼。一名地区法官裁定,Stability AI、Midjourney、DeviantArt 和 Runway AI 等公司未经许可使用艺术家的作品来训练自己的人工智能模型,侵犯了艺术家的版权。
4 ★ | 1 票