了解缓存的工作原理(第3部分)
了解缓存的工作原理(第1部分)
了解缓存的工作原理(第2部分)
在职的
CPU提取单元将寻找在L1指令缓存中执行的下一个指令。如果不存在,它将在L2缓存上搜索。之后,如果没有,它将必须访问RAM以加载指令。
当CPU从缓存加载请求或数据指令时,我们将调用“命中”,如果所请求的指令或数据不存在,并且CPU需要直接访问RAM以检索此数据,则称为“错过”。
显然,当您打开计算机时,缓存是完全空的,因此系统必须访问RAM - 这是不可避免的缓存失误。但是,在加载第一个指令后,此过程将开始。
当CPU从某个内存位置加载指令时,调用内存缓存控制器的电路将加载到存储器高速缓存中,一个小数据块在CPU刚刚加载的当前位置下方。由于程序通常是按顺序完成的,因此CPU将需要的下一个内存位置可能是刚刚加载的内存位置下方的位置。同样,由于内存高速缓存控制器已加载了CPU第一个位置下方的一些数据,因此下一个数据可能位于内存缓存内部,因此CPU无需访问RAM。为了获取数据:它已加载到CPU中的嵌入式内存缓存中,这使其可容纳内部时钟速率。
这一数量的数据称为流,通常为64个字节长。
除了加载少量数据外,内存控制器还试图猜测CPU接下来需要什么。一个称为预求路电路的电路将加载更多的数据,此前64个字节从RAM进入存储器缓存。如果该程序继续以这种顺序的方式从内存位置加载指令和数据,则CPU将事先将CPU询问的指令和数据事先加载到内存缓存中。
我们可以总结内存缓存的工作方式如下:
1。CPU需要存储在“ A”地址的指令或数据。
2。由于来自“ A”地址的内容在内存缓存内部没有,因此CPU必须直接从RAM获取。
3。缓存控制器将从“ A”地址开始到存储器缓存,从“ A”地址开始加载一条线(通常为64个字节)。它将加载比CPU所需的数据更多,因此,如果程序继续顺序运行(即需要地址+1),则CPU会询问的下一个指令或数据以前已加载在内存缓存中。
4。称为预求的电路将加载此行之后放置的多个数据,这意味着开始从地址A + 64开始加载内容到缓存中。为了给您一个例子,即pentium 4 CPU具有256个字节的预定量,因此可以在加载到高速缓存的数据流旁边加载256个字节。
如果程序顺序运行,则CPU将不需要直接访问RAM来获取数据,除非加载第一个指令 - 因为CPU所需的说明和数据。在CPU请求之前,将始终在内存缓存内。
尽管不运行的程序总是相同的,但有时它们可以从一个内存位置跳到另一个内存位置。主要缓存控制器的主要挑战是猜测解决CPU将会跳到的是什么,从而在CPU请求之前将该地址的内容加载到内存缓存中,以避免访问CPU。 RAM减少到系统的性能。此任务称为分支预测,所有现代CPU具有此功能。
现代CPU的命中率至少为80%,这意味着80%的时间CPU无法直接访问RAM,而是内存缓存。
组织内存缓存
内存缓存分为内部流,每个流的长度在16到128个字节之间,具体取决于CPU。对于大多数当前CPU,根据64个字节线(512位)组织内存缓存,因此在本教程的整个示例中,我们将使用64 Byte线路考虑内存缓存。 。在下面,我们将介绍当前市场上所有CPU的内存缓存的主要规格。
内存缓存512 kb L2分为8,192行。您应该注意,1KB为2 ^ 10或1024字节,而不是1,000字节,因此524.288 / 64 = 8192。我们将考虑示例中具有512 kb内存缓存L2的单核CPU。在图5中,我们模拟了此内存缓存的内部组织。

图5:如何组织L2内存缓存512 kb
内存缓存可以在三种不同的配置类型下工作:直接映射,全局链接和链接汇总(以多行)。
直接映射
直接映射是创建内存缓存的最简单方法。在此配置中,主RAM内存分为位于内存缓存内部的平等线路。如果我们有一个1GB RAM系统,则该1GB将分为8,192个块(假设内存缓存使用上面描述的配置),每个块具有128KB(1,073,741,824 / 8,192 = 131.072 = 131.072-注意1GB是2 ^ 30 bytes bytes by beb is 2 ^ 20 byte,请注意,如果您的系统具有512MB,则内存也将分为8,192个块,但这些块中的每个块仅为64 kb。我们已经证明了下面的图6中如何组织这一点。
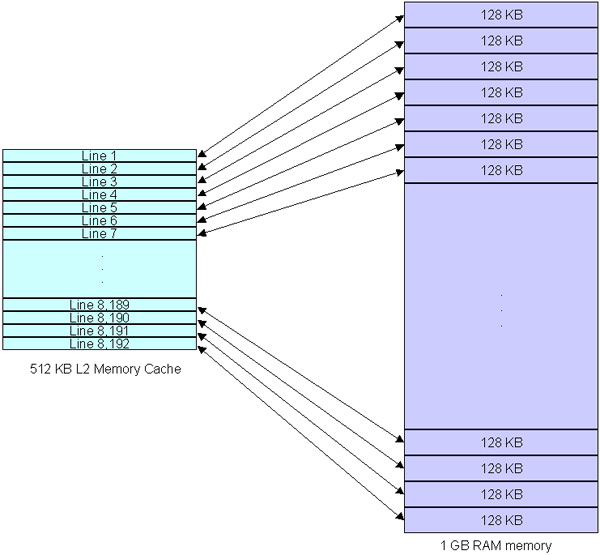
图6:如何直接映射缓存工作
直接映射的优点是它是最简单的方法。
当CPU从RAM请求某个地址(例如,1,000个地址)时,缓存控制器将从RAM内存加载一行(64个字节),并将此行存储在内存缓存(即从地址1,000)。至1,063,假设我们正在使用8位寻址方案。因此,如果CPU再次需要此地址的内容或某些后续地址(即1,000至1,063之间的地址),则它们将在缓存内部可用。
问题在于,如果CPU需要两个地址映射到同一缓存线,则会出现错过(此问题称为碰撞现象)。继续我们的示例,如果CPU需要1,000个地址,然后请求一个2,000个地址,则会出现一个失误,因为这两个地址在同一128KB块中,并且缓存内部的内容是从地址1,000开始的一行。这就是为什么缓存控制器从地址2,000加载一条线并将其存储在内存缓存的第一行中,从而删除了先前的内容,在我们的情况下,它是地址1,000的行。
也是一个问题。如果该程序的循环超过64个字节,则在整个循环期间也会错过。
例如,如果循环从地址1,000执行至地址1,100,则CPU必须在循环的持续时间内直接从RAM加载所有指令。由于缓存的内容将从1,000到1,063个地址,并且当CPU从1,100地址请求内容时,此问题将发生,因此它必须进入RAM以检索数据,然后控制器将加载地址从1,100加载至1,163。当CPU请求1,000个地址时,它将不得不返回RAM,因为缓存将没有地址1,000的数据组件。如果该循环执行1000次,则CPU将必须输入RAM以加载数据1,000次。
这就是为什么直接映射内存缓存效率较低且使用较少的原因。
整个协会
换句话说,总体链接配置在内存缓存线和RAM内存位置之间没有困难。缓存控制器可以存储任何地址。因此,上述问题不会发生。该配置是最有效的配置(即配置具有最高的命中率)。
换句话说,控制电路要复杂得多,因为它需要能够跟踪在内存缓存中加载哪些内存位置。这是引入当今广泛使用的混合解决方案(称为链接文件)的原因。
 了解缓存的工作原理(结尾部分)
了解缓存的工作原理(结尾部分)
你应该阅读
可能有兴趣
- 如何生产计算机芯片
您是否知道如何生产处理器,视频处理器,内存,芯片组等芯片?在本教程中,我们将介绍必要的信息,以便您了解该过程的基础知识。
- 核心2二重奏模型
Core 2 Duo处理器(代号Conroe)启动了新一代的Intel CPU建立在新的Core Architecture上(因为Core 2 Duo是台式机使用的第一个处理器)。使用此体系结构)以及Tuy&Ecir
- OSI参考模型中的硬件:1年级
开放系统互连(OSI)参考模型是由Open System InterConnect(OSI)开发的模型,该模型描述了如何将计算机上的数据传输到计算机上的应用程序。多么不同。 M&O
- OSI参考模型中的硬件:第2层
在本系列的上一部分中,我们引入了7层OSI参考模型和第一层,即物理层。在本系列的第二部分中,我们将从硬件的角度介绍第二层,数据链路层或数据链接。
- 关于串行ATA(SATA)的知识
串行ATA(串行高级技术附件)或SATA是创建的标准硬盘驱动器,以替换仍然称为IDE的平行ATA接口。 SATA的传输速率约为150mb / s或300 Mb / s,而先前技术的最高速度为133 Mb / s。本文将向您展示有关串行ATA所需的所有信息。
- OSI参考模型中的硬件:3年级
在第三部分中,我们将向您介绍三等阶层。网络类。网络层是将数据从一台计算机传输到另一台计算机的层。